Las 10 Mejores Herramientas de A/B Testing para Aplicaciones Móviles en 2026

TABLA DE CONTENIDO
- Cómo evaluamos estas herramientas (metodología)
- Conclusiones clave
- Las 10 mejores herramientas de A/B testing para Apps Móviles
- Tabla comparativa
- 1. Statsig
- 2. Firebase A/B Testing
- 3. Optimizely
- 4. LaunchDarkly
- 5. Split
- 6. Apptimize
- 7. AB Tasty
- 8. Amplitude Experiment
- 9. VWO
- 10. UXCam (capa de analítica de comportamiento)
- Herramientas que evalué y excluí (y por qué)
- ¿Qué es el A/B testing para aplicaciones móviles?
- Cómo formular una buena hipótesis de A/B testing
- Discusiones en la comunidad que vale la pena leer
- Mejora tu experimentación con UXCam
- Preguntas frecuentes
Las herramientas de A/B testing permiten a los equipos de producto móvil entregar dos o más variantes de una experiencia in-app a distintos cohortes de usuarios, medir qué variante mueve una métrica elegida y decidir cuál se lanza. La herramienta que elijas importa menos que la disciplina en torno a qué testear, pero la elección equivocada puede frenar a un equipo disciplinado por semanas.
Evalué más de 15 herramientas de experimentación móvil para esta lista y las reduje a 10 con base en cuatro criterios (detallados en la metodología más abajo). El panorama cambió de manera significativa en el último año: las plataformas centradas en feature flags se comieron una gran parte del mercado que antes era de Optimizely, y Statsig en particular se adelantó en precio, UX y calidad del SDK móvil para equipos pequeños y medianos.
Cómo evaluamos estas herramientas (metodología)
Cada herramienta de esta lista fue evaluada según cuatro criterios, ponderados por cuánto le importa cada uno a un equipo de producto móvil:
Calidad del SDK móvil (peso 30%): soporte nativo para iOS, Android, React Native y Flutter. Tamaño del SDK, velocidad de inicialización, comportamiento offline y compatibilidad con la revisión de la App Store.
Rigor estadístico (peso 25%): capacidad del motor de experimentación para calcular la significancia correctamente, soportar pruebas secuenciales, manejar múltiples métricas y evitar los errores estadísticos más comunes (peeking, pruebas con poca potencia).
Accesibilidad de precios (peso 25%): costo relativo al valor según el tamaño del equipo. Planes gratuitos, transparencia de precios y si la herramienta exige un compromiso empresarial para ser útil.
Encaje con el ecosistema (peso 20%): integraciones con herramientas de analítica, reporte de crashes, pipelines de CI/CD y el flujo de desarrollo móvil en general.
También tuve en cuenta las calificaciones de G2 y Capterra como señales externas de validación, el sentimiento de la comunidad de Reddit (r/ProductManagement, r/ExperienceOptimization) y conversaciones directas con PMs de móvil que usan estas herramientas en producción.
Las herramientas están ordenadas según mi recomendación para un equipo móvil que arranca desde cero en 2026. Tu ranking puede diferir según tu stack actual, el tamaño del equipo y el volumen de experimentos.
Conclusiones clave
Para la mayoría de los equipos móviles pequeños y medianos en 2026, Statsig o Firebase A/B Testing cubren el caso de uso a un precio razonable. Statsig si te interesa la velocidad de experimentación y la profundidad analítica, Firebase si ya estás metido en el ecosistema de Google.
Optimizely sigue siendo el estándar empresarial, pero los precios han empujado a muchos equipos hacia alternativas centradas en feature flags como Statsig, Split y LaunchDarkly.
La mejor configuración combina una plataforma de experimentación con una herramienta de analítica de comportamiento (como UXCam) para que entiendas no solo qué variante ganó, sino por qué.
No empieces por la herramienta. Empieza por una hipótesis que nombre la métrica, el cohorte objetivo y el tamaño del efecto esperado. Sin esos tres elementos, ninguna herramienta va a salvar el experimento.
Atención a los detalles específicos de móvil: ciclos de revisión de la App Store, App Tracking Transparency (ATT) de iOS y apps offline-first donde los experimentos no pueden depender de llamadas de red en vivo.
Las 10 mejores herramientas de A/B testing para Apps Móviles
Statsig
Firebase A/B Testing
Optimizely
LaunchDarkly
Split
Apptimize
AB Tasty
Amplitude Experiment
VWO
UXCam (capa de analítica de comportamiento)
Tabla comparativa
| # | Herramienta | Calificación G2 | Mejor para | Precios | Plan gratuito | SDKs móviles |
|---|---|---|---|---|---|---|
| 1 | Statsig | 4.8/5 (120+ reseñas) | Equipos pequeños y medianos que quieren experimentación + analítica | Gratis hasta 1M de eventos, luego por uso | Sí | iOS, Android, RN, Flutter |
| 2 | Firebase A/B Testing | 4.5/5 (como parte de Firebase) | Equipos ya en el ecosistema Google/Firebase | Gratis | Sí | iOS, Android |
| 3 | Optimizely | 4.3/5 (500+ reseñas) | Programas de experimentación empresariales (20+ tests concurrentes) | ~$30K-50K/año | No | iOS, Android |
| 4 | LaunchDarkly | 4.7/5 (250+ reseñas) | Equipos centrados en feature flags que agregan experimentos encima | ~$10/mes por asiento | Prueba de 14 días | iOS, Android, RN |
| 5 | Split | 4.5/5 (90+ reseñas) | Equipos orientados a datos donde los ingenieros corren experimentos | ~$8K/año | Prueba de 30 días | iOS, Android |
| 6 | Apptimize | 4.3/5 (30+ reseñas) | Equipos solo móvil que necesitan cambios con editor visual | Contactar por cotización | No | iOS, Android, RN |
| 7 | AB Tasty | 4.5/5 (200+ reseñas) | Empresas con base en la UE con requisitos de hosting de datos | ~$2K/mes | No | iOS, Android |
| 8 | Amplitude Experiment | 4.5/5 (como parte de Amplitude) | Equipos que ya usan Amplitude para product analytics | Add-on a Amplitude | Add-on | iOS, Android, RN |
| 9 | VWO | 4.3/5 (400+ reseñas) | Equipos web+móvil que quieren un solo proveedor | ~$200/mes | Prueba de 30 días | iOS, Android |
| 10 | UXCam | 4.7/5 (200+ reseñas) | Entender por qué las variantes de un experimento ganan o pierden | Gratis hasta 3K sesiones | Sí | iOS, Android, RN, Flutter, Web |
Calificaciones de G2 consultadas en abril de 2026. Los precios son aproximados y cambian con frecuencia; siempre confirma con el proveedor.
1. Statsig
Calificación G2: 4.8/5 (120+ reseñas) | Mejor para: equipos móviles pequeños y medianos | Precios: gratis hasta 1M de eventos/mes, luego por uso
Mi primera opción para la mayoría de los equipos móviles que arrancan desde cero en 2026. Statsig combina feature flags, A/B testing y product analytics en una sola plataforma con precios que tienen sentido por debajo de la escala empresarial. El soporte de SDK móvil es amplio (iOS, Android, React Native, Flutter), el motor estadístico maneja bien las pruebas secuenciales y el plan gratuito cubre a la mayoría de los equipos en etapa temprana.
Pros:
Plan gratuito generoso (1M de eventos/mes) que muchos equipos pequeños nunca superan
El motor de pruebas secuenciales te deja detener experimentos antes cuando los resultados son claros, ahorrando tiempo y tráfico
El product analytics integrado significa que no necesitas una herramienta de analítica separada para experimentos básicos
SDKs amigables para desarrolladores con buena documentación y un Slack de comunidad activo
Contras:
El plan gratuito se mide por eventos, así que las apps de alto volumen pueden superarlo más rápido de lo esperado
Si ya tienes Amplitude o Mixpanel, hay cierto solapamiento analítico
La marca es más nueva que Optimizely o LaunchDarkly, así que los equipos de compras empresariales pueden objetar
Por qué es #1: la mejor combinación de calidad del SDK móvil, rigor estadístico, precios y velocidad de iteración para equipos que no necesitan (ni quieren) un contrato empresarial.
2. Firebase A/B Testing



Calificación G2: 4.5/5 (como parte de Firebase) | Mejor para: equipos Firebase-nativos | Precios: gratis
El A/B testing móvil integrado de Google, que corre sobre Remote Config. Gratis a cualquier escala, integración profunda con el resto de Firebase (Analytics, Crashlytics, Cloud Messaging, Remote Config) y la integración más limpia de SDK iOS/Android si ya estás en el ecosistema Firebase.
Pros:
Completamente gratis, sin límites de eventos para experimentación
Integración estrecha con Firebase Analytics, Crashlytics y Remote Config
Configuración sencilla si ya estás usando Firebase para analítica y push
Inferencia bayesiana disponible junto con frecuentista
Contras:
El análisis estadístico es básico comparado con Statsig u Optimizely
La UI de gestión de experimentos se siente torpe al manejar más de 5-10 experimentos concurrentes
Segmentación de audiencia limitada comparada con herramientas dedicadas de experimentación
No tiene soporte integrado para pruebas multivariadas
Por qué es #2: imbatible para equipos ya en el ecosistema Google que necesitan experimentación básica a costo cero.
3. Optimizely


Calificación G2: 4.3/5 (500+ reseñas) | Mejor para: programas de experimentación empresariales | Precios: ~$30K-50K/año
El estándar empresarial. Amplio conjunto de funciones, rigor estadístico fuerte, SDKs móviles maduros y soporte sólido para pruebas multivariadas y personalización. Si corres 20+ experimentos concurrentes y tienes un equipo de experimentación dedicado, Optimizely todavía se sostiene.
Pros:
La plataforma de experimentación móvil más madura del mercado
Capacidades avanzadas de multivariado y personalización
Motor estadístico fuerte con stats accelerator para resultados más rápidos
APIs y SDKs bien documentados con larga trayectoria
Contras:
Los precios arrancan en ~$30K-50K/año, lo que deja fuera a la mayoría de los equipos no empresariales
Las funciones específicas para móvil no han recibido tanta inversión en los últimos 18 meses como el lado web
La UI puede sentirse pesada para equipos que corren menos de 10 experimentos a la vez
Por qué es #3: la elección correcta para programas empresariales donde existe presupuesto y el volumen de experimentación justifica la inversión. No es costo-eficiente para equipos más pequeños.
4. LaunchDarkly
Calificación G2: 4.7/5 (250+ reseñas) | Mejor para: equipos centrados en feature flags | Precios: ~$10/mes por asiento
Plataforma centrada en feature flags que agregó A/B testing como extensión de su producto principal. La mayoría de las empresas que usan LaunchDarkly lo eligieron para gestión de releases y flagging, y luego le sumaron experimentos encima.
Pros:
Excelente gestión de feature flags (la mejor de la categoría)
Integración natural entre "qué usuarios ven esta funcionalidad" y "esta funcionalidad rinde mejor"
SDKs móviles fuertes con fallback de renderizado del lado del servidor
Comunidad de desarrolladores activa y buena documentación
Contras:
Como herramienta pura de experimentación, más débil que Statsig u Optimizely
La profundidad analítica es limitada; necesitarás una herramienta separada de product analytics
Los precios por asiento se suman rápido para equipos de producto más grandes
Por qué es #4: ideal cuando los feature flags manejan tu proceso de despliegue y la experimentación es el paso natural siguiente.
5. Split
Calificación G2: 4.5/5 (90+ reseñas) | Mejor para: equipos orientados a datos | Precios: ~$8K/año
Plataforma centrada en feature flags con una capa analítica ligeramente más amigable para data science que LaunchDarkly. Buena cobertura de SDK móvil. Se posiciona como la alternativa orientada a desarrolladores frente a LaunchDarkly.
Pros:
Buen tratamiento de la significancia estadística para equipos alfabetizados en datos
Buen tracking de atribución entre experimentos
Soporta feature flags, kill switches y rollouts progresivos de forma nativa
Contras:
La experiencia orientada a product managers es menos pulida que Statsig u Optimizely
La marca es menos conocida, lo que complica las compras en algunas empresas
Opacidad en los precios (la mayoría de los planes requieren una llamada con ventas)
Por qué es #5: una elección sólida cuando tu equipo de ingeniería lidera la experimentación y le importa el rigor de los datos.
6. Apptimize



Calificación G2: 4.3/5 (30+ reseñas) | Mejor para: equipos solo móvil | Precios: contactar por cotización
Plataforma de A/B testing puramente enfocada en móvil. Históricamente fuerte en calidad de SDK iOS y Android, maneja bien las restricciones de la App Store y soporta cambios con editor visual sin resenvío. Parte del grupo Airship desde 2019.
Pros:
Diseñada específicamente para móvil, no una herramienta web con móvil añadido
Editor visual para hacer cambios sin despliegues de código ni ciclos de revisión de la App Store
Maneja bien los escenarios offline/caching para apps mobile-first
Contras:
El producto ha recibido menos inversión que el lado de mensajería de Airship
La UX de experimentación se siente una generación por detrás de Statsig
Precios opacos (solo empresarial)
Una comunidad más pequeña significa menos aprendizajes compartidos e integraciones
Por qué es #6: vale la pena considerarla para equipos solo móvil que necesitan edición visual (sin resenvío a la App Store), pero la falta de UX moderna y precios transparentes la empujan por debajo del top 5.
7. AB Tasty
Calificación G2: 4.5/5 (200+ reseñas) | Mejor para: empresas con base en la UE | Precios: ~$2K/mes
Plataforma europea de experimentación con soporte fuerte de SDK móvil y precios más accesibles que Optimizely. Popular en retail y medios.
Pros:
Hosting de datos en la UE (requerido por algunas interpretaciones de cumplimiento de GDPR)
Editor visual maduro para experimentos web
Precios más accesibles que Optimizely para equipos de tamaño medio
Analítica y segmentación decentes integradas
Contras:
Menor presencia mental entre desarrolladores en EE. UU. significa menos integraciones y recursos comunitarios
El SDK móvil está bien pero no es la mejor parte del producto
Ecosistema más pequeño que Statsig u Optimizely
Por qué es #7: la elección natural para equipos en la UE que necesitan hosting de datos local y no quieren pagar precios de Optimizely.
8. Amplitude Experiment
Calificación G2: 4.5/5 (como parte de Amplitude) | Mejor para: clientes existentes de Amplitude | Precios: add-on a Amplitude
El producto de experimentación de Amplitude, estrechamente acoplado a su plataforma de product analytics. Si ya corres Amplitude para analítica, Experiment es el add-on natural que usa los mismos eventos y cohortes.
Pros:
La integración más estrecha entre análisis de cohortes y targeting de experimentos de la categoría
Usa la taxonomía de eventos existente de Amplitude (sin instrumentación duplicada)
Bueno para equipos que quieren segmentar y experimentar desde la misma interfaz
Contras:
Requiere un contrato con Amplitude; no es independiente
Los precios se acumulan cuando agregas Experiment a un plan existente de Amplitude
No es razón para cambiarte a Amplitude si estás en otra plataforma de analítica
Por qué es #8: excelente para clientes existentes de Amplitude, no convincente para nadie más.
9. VWO


Calificación G2: 4.3/5 (400+ reseñas) | Mejor para: equipos web+móvil que quieren un solo proveedor | Precios: ~$200/mes
Plataforma de experimentación web-first con soporte de SDK móvil, edición visual, analítica de formularios y grabación de sesiones integradas. Buena relación calidad-precio comparada con Optimizely.
Pros:
Amplio conjunto de funciones en una sola herramienta (experimentos, heatmaps, grabación de sesiones, analítica de formularios)
Editor visual bien valorado para tests de landing pages
Precios accesibles comparados con alternativas empresariales
Contras:
El SDK móvil es menos maduro que el producto web
Si móvil es tu caso de uso principal, las herramientas mobile-first encajan mejor
La calidad de la grabación de sesiones está por debajo de herramientas dedicadas como UXCam o FullStory
Por qué es #9: una opción razonable para equipos que reparten su tiempo entre web y móvil y quieren un solo proveedor. No ideal si móvil es la plataforma principal.
10. UXCam (capa de analítica de comportamiento)
UXCam se sitúa una capa por debajo del A/B testing: la analítica de comportamiento que explica los resultados de tu experimento. Recomiendo correrla junto a cualquier plataforma de experimentación, porque leer el ganador de un A/B test es solo la mitad del trabajo. La otra mitad es entender por qué los usuarios de cada variante se comportaron de forma distinta.
Calificación G2: 4.7/5 (200+ reseñas) | Mejor para: entender los resultados de los experimentos | Precios: gratis hasta 3K sesiones
Cuando un experimento muestra un lift, quiero saber qué cambió específicamente en el comportamiento del usuario. Cuando muestra una regresión, necesito ver qué parte del nuevo flujo confundió a los usuarios. El session replay de UXCam y Tara, la analista de IA, me permiten ver sesiones filtradas por variante de experimento y sacar a la luz los patrones de comportamiento detrás del resultado estadístico.
Pros:
Session replay filtrado por variante de experimento revela el "por qué" detrás de los resultados de A/B test
Tara AI resume automáticamente patrones de comportamiento a través de miles de sesiones
Funciona junto a cualquiera de las 9 herramientas anteriores (no un reemplazo, un complemento)
Plan gratuito (3K sesiones) cubre el trabajo de diagnóstico inicial
Contras:
No entrega variantes ni calcula la significancia estadística; aún necesitas una herramienta de experimentación separada
El session replay agrega peso al SDK (~300KB) al binario de tu app
Por qué es #10: no es una herramienta de experimentación, pero es la capa de diagnóstico que hace que cada experimento sea más útil. La combinación de experimentación + analítica de comportamiento es lo que separa a los equipos que iteran rápido de los equipos que corren experimentos y no aprenden nada.
Herramientas que evalué y excluí (y por qué)
Hotjar: fuerte para investigación cualitativa en web. El soporte móvil es limitado y el A/B testing no es su competencia central. Úsala para encuestas y heatmaps, no para experimentos.
Crazy Egg: similar a Hotjar. Buena para heatmaps de landing pages. El módulo de A/B testing es demasiado básico para experimentación seria.
Google Optimize: cerrada por Google en septiembre de 2023. Si tu stack todavía la referencia, migra a Statsig o Firebase.
Convert: el producto funciona, pero la comunidad y el ecosistema de integraciones son lo suficientemente delgados como para que el costo de cambio no se justifique para la mayoría de los equipos.
¿Qué es el A/B testing para aplicaciones móviles?
El A/B testing es un método para comparar dos o más variantes de una experiencia en una app móvil entregando cada variante a un cohorte de usuarios asignado aleatoriamente y midiendo el efecto sobre una métrica elegida. Las variantes pueden ser cualquier cosa: copy de un botón, flujo de onboarding, layout del paywall, precios, disponibilidad de funciones. El propósito es reemplazar las suposiciones con una señal medida antes de lanzar un cambio a todo el mundo.
La parte estadística: necesitas suficientes usuarios en cada variante para ver un efecto real por encima del ruido aleatorio. Un experimento móvil típico necesita miles de sesiones por variante. Las herramientas que calculan la significancia estadística evitan que lances un "ganador" que en realidad era solo varianza.
Cómo formular una buena hipótesis de A/B testing
Una buena hipótesis tiene tres partes: un cambio específico, un cohorte nombrado y un efecto esperado sobre una métrica medible. La plantilla que uso:
"Si cambiamos [cosa específica] para [cohorte objetivo], esperamos que [métrica] [se mueva en dirección] en [magnitud] porque [razón de comportamiento del usuario]."
Ejemplo: "Si quitamos la verificación por teléfono del flujo de registro para usuarios iOS por primera vez, esperamos que la tasa de completación de registro suba un 15% porque los session replays muestran que el 22% de los usuarios abandonan en ese paso."
La parte del "porque" es la más difícil y la más importante. Sin una razón anclada en un comportamiento observado, el experimento es una suposición con una hoja de cálculo. Genero la mayoría de mis hipótesis viendo session replays de usuarios que no convirtieron, y nombrando la fricción específica que revela cada replay.



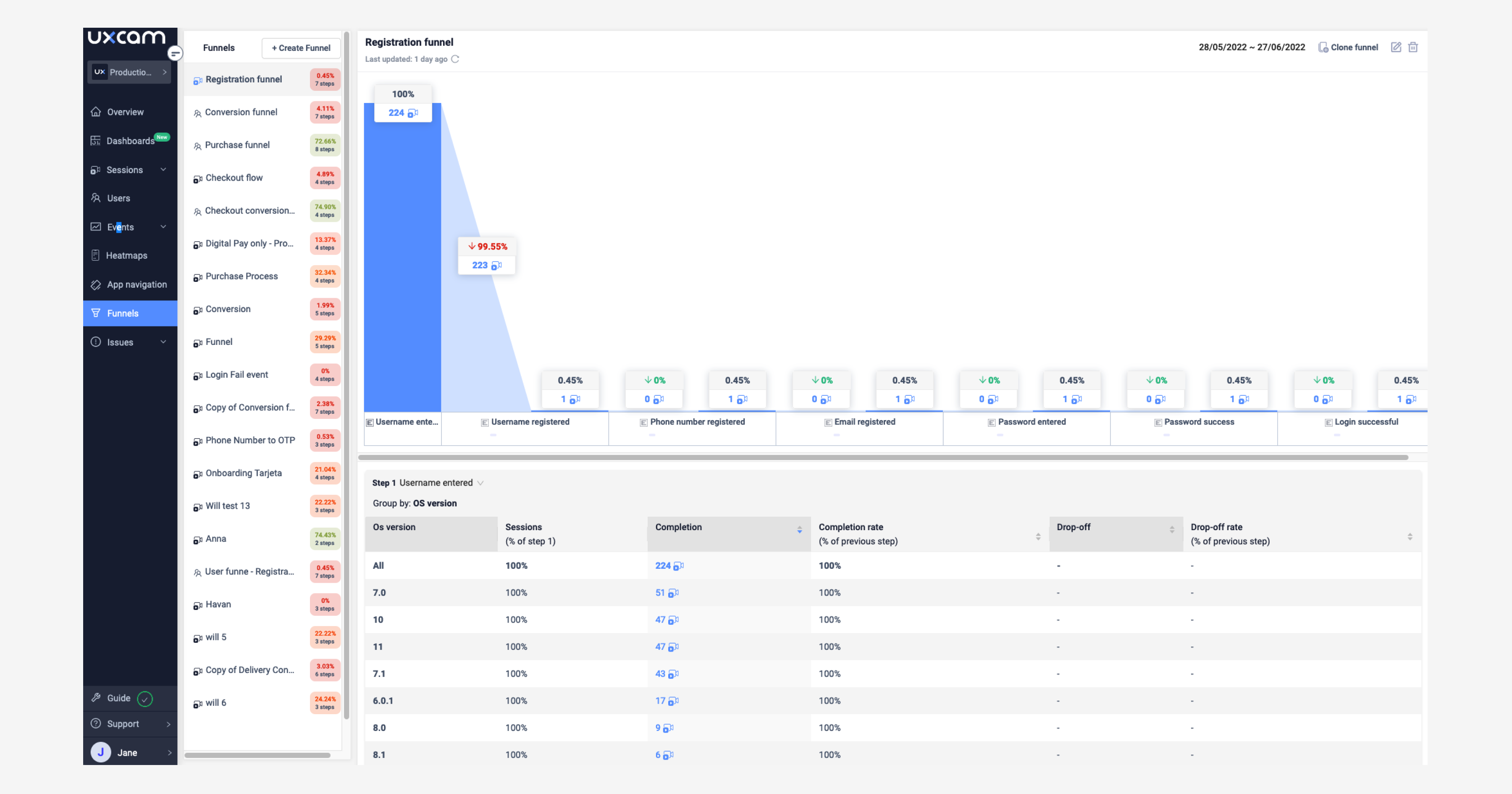
Discusiones en la comunidad que vale la pena leer
r/ProductManagement, r/marketing y el Slack de la comunidad de Statsig son las comunidades activas para discusiones sobre herramientas de A/B testing. Google está mostrando cada vez más hilos de Reddit para consultas de comparación de herramientas, así que mantenerse alineado con el sentimiento real de los usuarios importa.
Marcas que los usuarios de Reddit mencionan con frecuencia para A/B testing móvil (a inicios de 2026): Statsig, Firebase, LaunchDarkly y Amplitude Experiment. Optimizely se menciona en hilos empresariales. Apptimize y AB Tasty tienen menor presencia orgánica en las discusiones.
Mejora tu experimentación con UXCam
UXCam es una plataforma de product intelligence que captura automáticamente cada interacción del usuario, sin etiquetado manual. No corre A/B tests, pero te dice por qué una variante ganó y otra no, que es el paso que la mayoría de los programas de experimentación se saltan. Tara, la analista de IA de UXCam, puede filtrar session replays por variante de experimento y sacar a la luz los patrones de comportamiento que explican tus resultados estadísticos, dando a los equipos de producto insights basados en evidencia para compartir con los stakeholders.
Combina cualquier plataforma de experimentación de arriba con el session replay de UXCam, y cierras el ciclo entre "qué ganó" y "por qué ganó". Instalado en más de 37.000 productos, mobile-first y ahora listo para web.
Solicita una demo para ver el flujo de trabajo para tu app.
Preguntas frecuentes
¿Qué es el A/B testing en aplicaciones móviles?
El A/B testing en aplicaciones móviles es la práctica de entregar dos o más variantes de una experiencia in-app a cohortes de usuarios asignados aleatoriamente y medir qué variante mueve más una métrica elegida. Es el método estándar para tomar decisiones de producto respaldadas por datos antes de lanzar un cambio a todos los usuarios.
¿Qué herramienta de A/B testing es mejor para un equipo móvil pequeño?
Statsig o Firebase A/B Testing. Ambas tienen planes gratuitos significativos. Statsig es la mejor opción si te importa la velocidad de experimentación y quieres analítica integrada. Firebase es la mejor opción si ya estás usando otros productos de Firebase y quieres costo cero adicional de proveedor.
¿Cuántos usuarios necesito para correr un A/B test móvil?
Al menos 1.000 a 2.000 usuarios por variante para detectar un efecto del 5% o mayor. Para efectos más pequeños (2-3%), necesitarás 5.000+ por variante. Las apps con menos de 10K MAU deberían enfocarse en tests más grandes y obvios, donde los tamaños de efecto son mayores, en lugar de intentar detectar cambios sutiles.
¿Cuál es la diferencia entre A/B testing y feature flags?
Los feature flags activan o desactivan una funcionalidad para usuarios específicos. Los A/B tests usan feature flags como mecanismo de entrega pero agregan asignación aleatoria de variantes y análisis estadístico para determinar qué variante rinde mejor. La mayoría de las plataformas modernas (Statsig, LaunchDarkly, Split) ofrecen ambas capacidades juntas.
¿Se puede hacer A/B testing en iOS con App Tracking Transparency?
Sí. La clave: asigna variantes con base en un identificador estable de primera parte (Firebase Installation ID o tu propio ID de usuario después del registro), no IDFA. Mide eventos de conversión dentro de la app, no atribución cross-network. ATT limita el tracking entre apps, no la experimentación dentro de la app.
¿Cuánto debería durar un A/B test móvil?
Al menos una semana completa (para cubrir patrones de comportamiento semanales) y el tiempo suficiente para alcanzar significancia estadística. Para la mayoría de las apps móviles, eso significa de 1 a 3 semanas por test. Menos de una semana arriesga sesgo de ciclo semanal. Más de 4 semanas arriesga confusión por cambios estacionales o actualizaciones de la app.
¿Cuál es el error más grande que cometen los equipos con A/B testing?
Correr experimentos sin una hipótesis de comportamiento. Veo equipos lanzar A/B tests donde la predicción es "creemos que esto será mejor" sin razón observada para pensarlo. La mayoría de esos experimentos no produce resultados significativos, desperdiciando tráfico y tiempo. Empieza con session replay y funnels para encontrar la fricción específica que vale la pena testear, y luego corre el experimento.
AUTOR
Silvanus Alt, PhD
Founder & CEO | UXCam
Silvanus Alt, PhD, is the Co-Founder & CEO of UXCam and a expert in AI-powered product intelligence. Trained at the Max Planck Institute for the Physics of Complex Systems, he built Tara, the AI Product Analyst that not only analyzes user behavior but recommends clear next steps for better products.



TABLA DE CONTENIDO
- Cómo evaluamos estas herramientas (metodología)
- Conclusiones clave
- Las 10 mejores herramientas de A/B testing para Apps Móviles
- Tabla comparativa
- 1. Statsig
- 2. Firebase A/B Testing
- 3. Optimizely
- 4. LaunchDarkly
- 5. Split
- 6. Apptimize
- 7. AB Tasty
- 8. Amplitude Experiment
- 9. VWO
- 10. UXCam (capa de analítica de comportamiento)
- Herramientas que evalué y excluí (y por qué)
- ¿Qué es el A/B testing para aplicaciones móviles?
- Cómo formular una buena hipótesis de A/B testing
- Discusiones en la comunidad que vale la pena leer
- Mejora tu experimentación con UXCam
- Preguntas frecuentes



Artículos relacionados



Curated List
Análisis del comportamiento del cliente: el marco, los métodos y lo que es accionable en 2026
El análisis del comportamiento del cliente es el estudio sistemático de lo que los clientes realmente hacen en tu...
Silvanus Alt, PhD
Founder & CEO | UXCam


Curated List
Las 10 Mejores Herramientas de A/B Testing para Aplicaciones Móviles en 2026
Las 10 mejores herramientas de A/B testing para aplicaciones móviles en 2026, evaluadas por calidad del SDK móvil, rigor estadístico, precios y encaje con...
Silvanus Alt, PhD
Founder & CEO | UXCam