Cómo Medir el Rendimiento de una App Móvil: 18 Métricas Que Importan (2026)

TABLA DE CONTENIDO
- Conclusiones clave
- El catálogo de métricas de rendimiento
- Bonus: las métricas de capa de negocio
- Presupuestos de Rendimiento por Plataforma
- Herramientas APM y RUM comparadas
- Benchmarking por clase de dispositivo
- Atrapando regresiones de rendimiento en CI/CD
- Rendimiento Percibido vs Técnico
- El modelo de madurez de rendimiento
- 10 errores comunes de rendimiento móvil
- Entendiendo las Métricas de Rendimiento
- Cómo Medir el Rendimiento de Apps Efectivamente
- Mide el rendimiento de tu app móvil con UXCam
- Preguntas frecuentes



Las métricas de rendimiento de apps móviles miden qué tan rápida, confiable y atractiva se siente una aplicación móvil para los usuarios. El "rendimiento" en realidad cubre varias capas superpuestas: rendimiento técnico (tasa de frames, memoria, latencia de API), rendimiento de arranque (tiempo de cold start), confiabilidad (sesiones sin crashes, tasa de ANR), rendimiento de negocio (ingresos, retención, LTV) y rendimiento percibido (rage taps, congelamientos de UI, fricción de navegación). Saber qué capa estás midiendo es la diferencia entre "necesitamos hacer la app más rápida" y "necesitamos reducir el cold start en Android por debajo de 2 segundos en dispositivos de gama media".
He auditado configuraciones de medición de rendimiento en docenas de equipos móviles, y el patrón es consistente. Los equipos que entregan más rápido miden lo que los usuarios sienten, no solo lo que dice su dashboard de APM. Esta guía cubre las métricas de rendimiento que vale la pena monitorear en 2026, cómo calcular cada una, a qué rangos apuntar y cómo convertir un dashboard de rendimiento en un ciclo de mejora accionable. Las métricas aplican por igual a iOS, Android y apps híbridas.
Conclusiones clave
El rendimiento de una app móvil son cinco capas: técnica (tasa de frames, memoria), arranque (cold start), confiabilidad (tasa de crashes), negocio (ingresos, retención) y percibida (rage taps, fricción). Monitorea al menos una métrica de cada una.
La métrica de rendimiento con mayor impacto en retención es el tiempo de cold start. Los usuarios deciden si interactuar dentro de los primeros 3 segundos, y un cold start por encima de 2.5 segundos perjudica de forma medible la retención de la primera sesión.
Una tasa de usuarios sin crashes por debajo del 99% es el umbral en el que deberías estar alertando a alguien. Por debajo del 97% es una emergencia.
Las señales cualitativas de rendimiento (rage taps, congelamientos de UI) suelen detectar problemas antes que las métricas cuantitativas. Un pico de rage taps en una pantalla específica es una pista diagnóstica que ningún promedio de dashboard va a mostrar.
Establece presupuestos de rendimiento por clase de dispositivo y hazlos cumplir en CI. Un Android de gama media es el techo para el rendimiento en el mundo real, no los iPhones más modernos.
El catálogo de métricas de rendimiento
Las secciones a continuación desglosan 18 señales que monitoreo en equipos móviles. Cada una cubre qué es la métrica, por qué importa, un rango objetivo saludable y las herramientas que uso para capturarla de forma limpia.
1. Tiempo de cold start (p50 y p95)
El cold start es el tiempo desde el toque en el ícono de la app hasta el primer frame totalmente interactivo después de que el sistema operativo terminó el proceso. Lo mido tanto en p50 (la experiencia mediana del usuario) como en p95 (la cola lenta donde se esconde el churn), porque una mediana saludable con frecuencia oculta una cola brutal.
Esta es la métrica de arranque más importante, y la documentación de Android vitals de Google la trata como una señal de confiabilidad de primer nivel. Los cold starts por encima de 5 segundos se marcan como "excesivos" en Play Console, y mis propios datos coinciden: la retención de primera sesión cae abruptamente una vez que el p95 sube de 2.5 segundos. Apunto a un p50 por debajo de 1.2s y un p95 por debajo de 2s en la clase de dispositivo objetivo. Cualquier cosa por encima de 3s en p95 es un bloqueador de release.
Para instrumentarlo, iOS expone el cold start vía
de , y Android expone más las vitals de arranque de Play Console. Cualquier APM decente, incluyendo Firebase Performance, Sentry Mobile, Datadog Mobile RUM, Embrace y UXCam, captura esto automáticamente.2. Tiempo de warm start
El warm start es el tiempo desde el toque hasta el estado interactivo cuando el proceso sigue residente en memoria pero la activity o scene se recrea. Importa más de lo que la mayoría de los equipos cree, porque los warm starts dominan el uso activo diario. Un usuario que abre la app 8 veces al día ve 1 cold start y 7 warm starts. Si el warm start es torpe, la app se siente rota aunque el cold start sea excelente.
Apunto a un p95 por debajo de 800ms, y cualquier cosa por encima de 1.5s se nota. Las mismas herramientas que capturan el cold start lo capturan, separado por tipo de arranque, y el trace
de Firebase es un buen lugar para monitorearlo.3. Time to interactive (TTI)
El TTI mide el tiempo desde la navegación a una pantalla hasta el punto en que el usuario puede tocar o hacer scroll sin trabones. Es distinto de "pantalla renderizada", que solo te dice que los píxeles están en pantalla. Una pantalla puede renderizarse de inmediato pero seguir bloqueada esperando una llamada de red o una tarea pesada en el main thread, y el TTI es lo que atrapa la brecha entre "se ve cargada" y "responde al input".
El objetivo que mantengo con los equipos es por debajo de 2s en p95 para cualquier pantalla primaria, y por debajo de 1s para pantallas de alto tráfico como home o feed. Para instrumentarlo, envuelve tu handler de navegación con un timestamp y emite el evento "interactivo" una vez que el backlog del main thread se drene y las llamadas de red bloqueantes se completen. UXCam captura esto automáticamente a través de su medición de transición de pantallas.
4. Tiempo hasta la primera acción
El tiempo hasta la primera acción mide el tiempo desde que aparece la pantalla hasta el primer toque o scroll significativo del usuario. Es una señal conductual más que técnica, y emparejarla con el TTI es donde se gana su lugar. Si el TTI es 1.2s pero el tiempo hasta la primera acción es 4.8s, los usuarios están dudando, y eso usualmente significa que la UI no está clara en lugar de que sea lenta.
Los objetivos varían por tipo de pantalla: en una pantalla de acción central, por debajo de 3s es saludable, mientras que cualquier cosa por encima de 8s sugiere un problema de UX más que de rendimiento. La analítica de sesiones de UXCam muestra esto directamente, y Amplitude o Mixpanel pueden reconstruirlo desde los pasos del funnel.
5. Tasa de frames durante el scroll
Es el promedio de frames por segundo mientras el usuario está haciendo scroll activamente en superficies centrales como feeds, listas o grillas de productos. Las pantallas modernas de Android e iPhone corren a 90Hz o 120Hz, así que un feed por debajo de 60fps en un dispositivo de 120Hz se siente notoriamente mal. El scroll también es el gesto más ejecutado en la mayoría de las apps, lo que significa que el trabón aquí golpea cada sesión.
Apunto a 58fps+ en dispositivos de 60Hz y 90fps+ en dispositivos de 120Hz, siempre medido en un Android de gama media en lugar de en uno de línea alta. La API de Android y la librería JankStats manejan la instrumentación, y en iOS es
más los hitches de animación de .6. Porcentaje de jank (slow y frozen frames)
El porcentaje de jank es la proporción de frames que tardaron más de 16.67ms (lentos) o 700ms (congelados) en renderizarse, usando las definiciones de Google Play. Play Console marca apps con slow frames por encima del 25% de las sesiones o frozen frames por encima del 0.1%, pero yo mantengo a los equipos en una barra más estricta: slow frames por debajo del 10% y frozen frames por debajo del 0.05%.
La razón por la que esto importa más que los fps brutos es simple: los usuarios no sienten el "fps promedio", sienten los frames malos. Una lista que corre a 120fps la mayor parte del tiempo pero tartamudea por 200ms en cada scroll se siente peor que una estable a 60fps.
7. Tasa de ANR (Android)
Application Not Responding, o ANR, es lo que Android dispara cuando el main thread está bloqueado por 5+ segundos en un evento de UI o 10+ segundos en un broadcast receiver. Los umbrales de Android vitals de Google Play ponen el techo en 0.47% de tasa de ANR percibida por el usuario, por encima de la cual Play muestra una advertencia a los usuarios en la tienda.
Firebase Crashlytics, Sentry, Bugsnag y Google Play Console reportan los ANRs con el stack capturado en el momento del congelamiento, así que no hay excusa para estar a ciegas aquí.
8. Tasa de hangs (iOS)
La tasa de hangs es el equivalente iOS del ANR.
reporta hangs cuando el main thread está sin respuesta por 250ms+ (micro-hang) o 2s+ (hang completo). Mantengo la tasa general de hangs por debajo del 0.1% de las sesiones. El Xcode Organizer de Apple marca los hangs como una métrica de calidad de release junto con los crashes, y vía MetricKit está expuesto por la mayoría de los APMs móviles.9. Tasa de usuarios sin crashes
La tasa de usuarios sin crashes es simplemente el porcentaje de usuarios con cero crashes en el período, calculada como usuarios-sin-crashes divididos por usuarios totales, por 100. La mantengo por encima del 99% diariamente. La razón por la que es crítica para la retención y no solo una métrica de confiabilidad: los usuarios que sufren un crash en la sesión uno churneán aproximadamente al triple de la tasa de los usuarios que no.



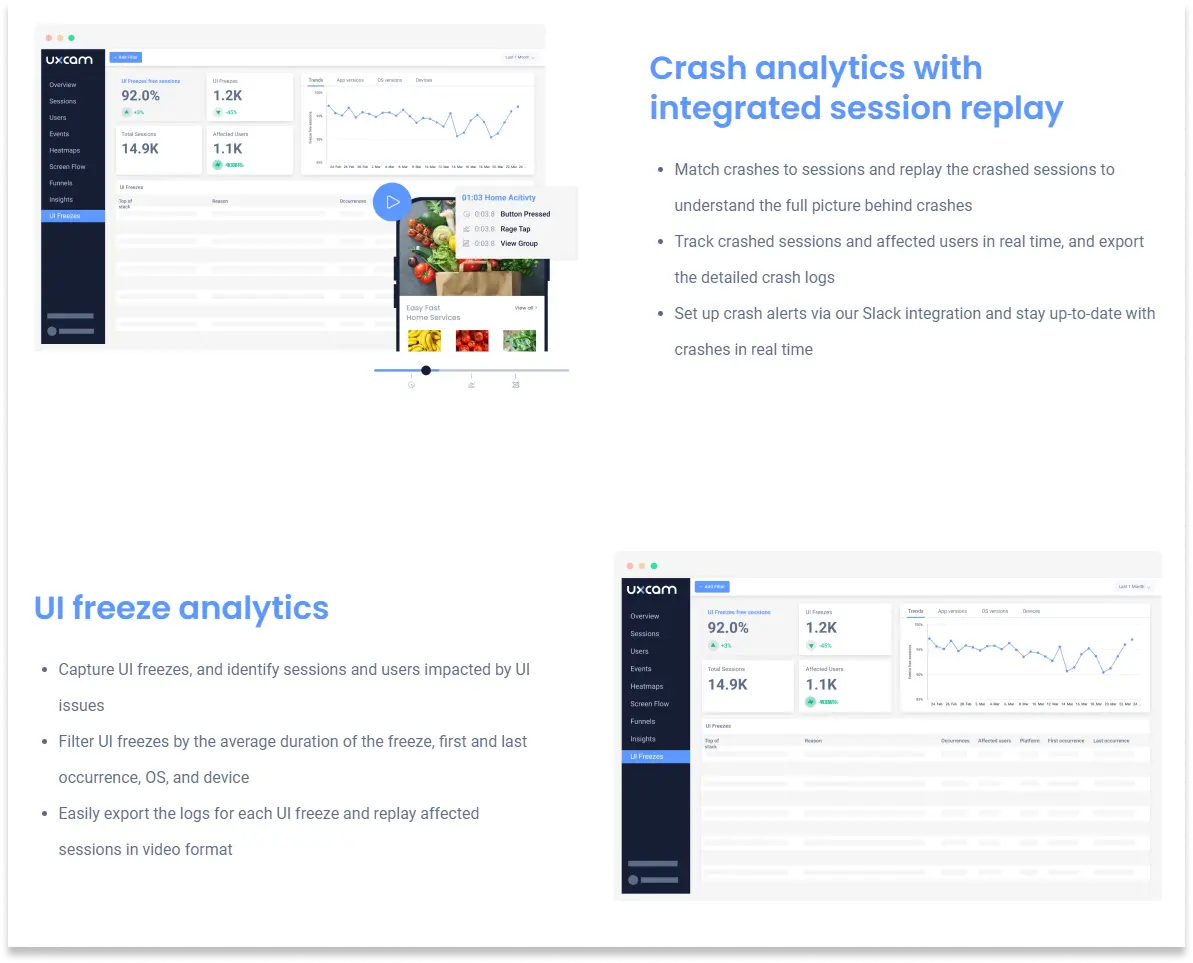
10. Tasa de sesiones sin crashes
La tasa de sesiones sin crashes es sesiones-sin-crashes divididas por sesiones totales, por 100, y apunto por encima del 99.5%. Da una vista sutilmente diferente que los usuarios sin crashes. Un solo usuario puede tener muchas sesiones sin crashes más una sesión con crash, así que la métrica de sesión separa "qué tan seguido ocurren los crashes" de "qué proporción de usuarios se topa con uno". Conviene monitorear ambas.
11. Uso máximo de memoria y terminaciones por memoria baja
El pico de memoria es la RAM máxima usada por la app durante una sesión típica, y las terminaciones por memoria baja son la tasa de kills a nivel del OS (jetsam en iOS, OOM kills en Android). Para la mayoría de las apps de consumo, apunto a un pico de memoria por debajo de 200MB y terminaciones por memoria baja por debajo del 0.2% de las sesiones en dispositivos de entrada.
Esto importa porque los picos de memoria causan crashes y terminaciones en primer plano en dispositivos con poca memoria, que son la mayoría de la base de instalación global. Los kills de jetsam de iOS son particularmente insidiosos porque son invisibles para el crash reporting: el OS mata el proceso limpiamente, y
es la única forma de verlos. En Android, y Firebase Performance hacen el trabajo; en iOS, más las allocations de Xcode Instruments.12. Consumo de batería por sesión
El consumo de batería mide los miliamperios-hora consumidos por minuto de uso en primer plano, normalizado entre clases de dispositivos. La batería es el asesino silencioso de la retención. Los usuarios rara vez se quejan específicamente de la batería, pero desinstalan apps a las que culpan por el consumo. El Battery Historian de Android y el
más de iOS dan los datos crudos.Mis objetivos: por debajo del 4% de batería por sesión de 30 minutos en dispositivos de referencia, y consumo en segundo plano por debajo del 0.5% por hora cuando está inactiva.
13. Tasa de errores de red
La tasa de errores de red es el porcentaje de llamadas HTTP que retornan 4xx, 5xx, timeout o falla de DNS. Cada request fallido es una funcionalidad que no funcionó para un usuario, y el session replay emparejado con los logs de errores de red muestra exactamente qué intentó hacer el usuario y qué vio en su lugar.
Mantengo los 5xx y timeouts combinados por debajo del 1%, con los 4xx por debajo del 5% y mayormente atribuibles a expiración de auth. Firebase Performance network monitoring, Datadog RUM, New Relic Mobile y la captura de red de UXCam muestran esto.
14. Latencia de API (p50, p95, p99)
La latencia de API es el tiempo desde que la app dispara un request hasta recibir una respuesta utilizable, medido del lado del cliente en lugar del lado del servidor. Los dashboards del lado del servidor casi siempre se ven más saludables que los del lado del cliente porque se pierden el tránsito de red y el DNS. Mide donde el usuario realmente experimenta la llamada.
Mis objetivos: p95 por debajo de 500ms para llamadas primarias de API y p99 por debajo de 1.5s. La latencia del backend se acumula: una consulta de base de datos de 200ms más 200ms de red más 200ms de renderizado del cliente se siente lenta para cuando el usuario ve algo.
15. Tamaño de descarga de assets y payload de arranque
Son los bytes descargados en el primer arranque más los bytes por sesión típica. Apunto a un payload de primer arranque por debajo de 15MB en datos celulares y un payload por sesión por debajo de 2MB para apps de contenido (más alto para medios).
El payload es un proxy del rendimiento en redes lentas. En mercados donde el 3G todavía es común, una descarga de primer arranque de 40MB es una fuga del funnel. Los Android App Bundles y los recursos bajo demanda de iOS te permiten diferir assets no críticos hasta que realmente se necesiten.
16. Tasa de aciertos en cache
La tasa de aciertos en cache es el porcentaje de requests de datos servidos desde el cache local en lugar de la red. Por encima del 60% es saludable para contenido que no necesita ser en tiempo real, y los caches de imágenes deberían estar por encima del 85%.
Un cache miss es un usuario esperando por red, y cada cache hit es una ganancia de rendimiento percibido. Librerías como Coil en Android y Kingfisher en iOS exponen telemetría de tasa de aciertos de forma nativa.
17. Tasa de rage taps
La tasa de rage taps es la proporción de sesiones con al menos un evento de rage tap, calculada como sesiones-con-rage divididas por sesiones totales, por 100. Un rage tap es 4+ toques en un segundo sobre el mismo elemento de UI, que indica frustración con una interacción que no responde o que se malentendió. Issue Analytics de UXCam los muestra automáticamente y los rankea por impacto de negocio.
Un pico de rage taps en un botón específico es una de las pistas diagnósticas más rápidas en el trabajo de rendimiento móvil. El usuario esperaba que pasara algo y no pasó; la pregunta es por qué.
18. Tasa de congelamientos de UI
La tasa de congelamientos de UI es el porcentaje de sesiones con al menos un congelamiento de UI de más de 2 segundos. Los congelamientos de UI son momentos en los que la app deja de responder al input por un instante. Rara vez crashean la app, así que el crash reporting los pierde por completo. El session replay los captura con claridad. Apunto por debajo del 1%.
Bonus: las métricas de capa de negocio
El rendimiento escala hasta resultados de negocio, y estas tres métricas completan la imagen.
Retención de la app (día 1, día 7, día 30)



La retención es usuarios-de-la-cohorte-X-aún-activos-al-día-N dividido por usuarios-totales-en-la-cohorte-X, por 100. Es la señal aguas abajo definitiva de la calidad del rendimiento. Los usuarios no vuelven a las apps que se sienten rotas. Para rangos detallados por categoría, consulta la guía de benchmarks de retención de apps móviles.
Duración y profundidad de sesión
La duración de sesión es el tiempo promedio por sesión, y la profundidad de sesión es el promedio de pantallas o acciones por sesión. Ambas son señales de engagement con implicancias directas de rendimiento. Cuando la duración de sesión cae, una regresión de rendimiento suele ser la causa.



CAC y ROAS
El costo de adquisición de clientes es el gasto de adquisición dividido por los nuevos usuarios adquiridos en el mismo período. El retorno sobre el gasto publicitario son los ingresos generados divididos por el gasto en publicidad. Si el CAC sube sin un incremento correspondiente en LTV, la eficiencia de adquisición está empeorando. Si el ROAS cae por debajo de 3:1, el canal de marketing está bajo agua.
Presupuestos de Rendimiento por Plataforma
Un presupuesto de rendimiento es un umbral duro que un release no puede cruzar sin aprobación explícita. Sin presupuestos, cada sprint erosiona el rendimiento por unos milisegundos y nadie se da cuenta hasta que la app se siente lenta seis meses después.
Establezco presupuestos por clase de dispositivo, porque "la app es rápida" en un iPhone 15 Pro significa muy poco cuando el 40% de los usuarios están en un Redmi Note del 2021.
Presupuestos iOS (iPhones recientes, iOS 17+)
Cold start p95: 1.2s
Warm start p95: 500ms
TTI para pantallas primarias: 1s
Tasa de hangs: por debajo del 0.05%
Pico de memoria: 180MB
Sesiones sin crashes: 99.7%
Las Directrices de Interfaz Humana de Apple definen implícitamente la capacidad de respuesta. Las interacciones deberían sentirse inmediatas, lo que internamente se traduce a menos de 400ms desde el toque hasta el feedback visible.
Presupuestos Android de gama media (Samsung serie A, Pixel 6a, Redmi Note 12)
Cold start p95: 2s
Warm start p95: 900ms
TTI: 2s
Tasa de ANR: por debajo del 0.47% (umbral de Play Console)
Frozen frames: por debajo del 0.1% de las sesiones
Pico de memoria: 220MB
Sesiones sin crashes: 99.5%
Presupuestos Android de gama baja (Android Go, <3GB RAM)
Cold start p95: 3.5s (realista, no aspiracional)
Pico de memoria: 120MB
Tasa de kills por memoria baja: por debajo del 1% de las sesiones
Payload de red por sesión: por debajo de 1.5MB
Web móvil (PWA o versión web móvil)
Usa Core Web Vitals como línea base: LCP por debajo de 2.5s, INP por debajo de 200ms, CLS por debajo de 0.1. Estos son los umbrales públicos de ranking de búsqueda de Google y un piso razonable para cualquier superficie web móvil.
Herramientas APM y RUM comparadas
No hay una sola herramienta que haga todo bien. La mayoría de los equipos maduros corre un APM, un reportador de crashes (a veces la misma herramienta) y una plataforma conductual como UXCam.
Firebase Performance Monitoring es gratis e integrado con Crashlytics, lo que lo hace una buena línea base para cold start, llamadas de red y traces personalizados. La retención histórica es limitada y las alertas son débiles, así que funciona mejor como APM inicial o como segunda opinión junto a una herramienta paga.
Sentry es fuerte en crashes y errores con una historia de rendimiento en crecimiento alrededor de transacciones y profiling. La experiencia de desarrollador y el SDK son limpios, pero puede ponerse caro a escala porque el pricing es basado en eventos.
Datadog Mobile RUM es de nivel empresarial y ata la telemetría móvil al APM de backend en la misma cuenta. Es caro, y se luce mejor cuando ya estás estandarizado en Datadog para la observabilidad del servidor.
New Relic Mobile está posicionado de forma similar pero con pricing basado en usuarios en lugar de eventos. La captura de crashes y red es sólida, aunque la UI se siente anticuada comparada con herramientas más nuevas.
Embrace es para móvil y web, construido por ex-ingenieros de Scopely, y va profundo en la confiabilidad a nivel de sesión. Es fuerte en la pregunta de "por qué la sesión de este usuario se degradó", y una buena elección si móvil es tu superficie principal y quieres profundidad sobre amplitud.
Bugsnag maneja el crash reporting con stability scoring. Ahora es propiedad de SmartBear, y es simple y confiable, aunque menos ambicioso en rendimiento que Sentry o Datadog.
Instabug combina reportes de bugs dentro de la app con monitoreo de rendimiento y crashes. Es popular en mercados emergentes, y el flujo de feedback dentro de la app es su diferenciador.
UXCam es una plataforma de product intelligence que cubre session replay, heatmaps e issue analytics. Captura contexto de crashes, rage taps, congelamientos de UI, TTI a nivel de pantalla y errores de red automáticamente, con Tara AI sentada encima para mostrar anomalías en lenguaje claro. La uso junto con un APM técnico, no como reemplazo. El replay es lo clave: un ticket de crash con el replay adjunto se arregla 3 veces más rápido que uno sin él.
Benchmarking por clase de dispositivo
Las métricas de rendimiento agregadas mienten. Si el 55% de tus usuarios están en iOS y la app es rápida ahí, el p95 general se ve bien aunque Android esté catastrófico.
Por qué el Android de gama media debería definir tu techo
Globalmente, el dispositivo Android mediano tiene 4GB de RAM, un chipset Snapdragon o Mediatek de la era 2020 y 64GB de almacenamiento. Si tu app está construida y probada solo en Pixel 8 Pros y iPhone 15s, cada release va a degradar silenciosamente la experiencia para la mayoría de tu base de instalación.
Establezco el techo de rendimiento usando un Samsung Galaxy A24, Redmi Note 12 o equivalente. Si va fluido ahí, va a ir fluido en todas partes.
Estrategia de muestreo
No ponderes las métricas de rendimiento solo por conteo de sesiones. Pondera por importancia estratégica: los top 5 dispositivos por usuarios activos (usualmente 40-50% de tu base), el dispositivo principal en cada uno de tus 3 principales mercados por ingresos, un dispositivo de referencia de gama baja (Android Go o equivalente) y el último flagship de cada OS para compatibilidad futura. Eso suelen ser 8-10 dispositivos de referencia, y cualquier regresión en cualquiera de ellos debería aparecer en tu reporte de release.
Laboratorios sintéticos de dispositivos
Para testing previo al release, los laboratorios de dispositivos en la nube te permiten correr scripts automatizados en cientos de dispositivos. Firebase Test Lab está integrado con el ecosistema de Google y es fuerte en Android pero limitado en iOS. BrowserStack App Live tiene un gran inventario de dispositivos y una buena UI para testing manual. LambdaTest tiene precios competitivos con buena integración de CI. AWS Device Farm es una buena opción si ya estás en AWS.
Los datos de usuarios reales siguen superando a los sintéticos para medición post-release, pero los sintéticos atrapan las regresiones obvias antes de que salgan.
Atrapando regresiones de rendimiento en CI/CD
El momento más barato para arreglar una regresión de rendimiento es antes de que se mergee. El más caro es después de que llegue al 100% de los usuarios.
Presupuestos de rendimiento pre-merge
Corre una suite ligera de perf en cada PR: cold start en un emulador de referencia, pico de memoria tras una sesión scripteada de 2 minutos, delta de tamaño del binario. Si se excede cualquier presupuesto, bloquea el merge o requiere una etiqueta como
. Emerge Tools maneja regresiones de tamaño de binario y tiempo de arranque, Reassure cubre React Native, y Firebase Test Lab Benchmark funciona para Android.Captura de flamegraph en regresiones
Cuando se detecta una regresión, captura automáticamente un perfil de systrace o Instruments desde la corrida de CI. Un flamegraph adjunto a la build fallida convierte una investigación de dos días en una de 10 minutos.
Rollouts escalonados
No publiques nuevos releases al 100% de inmediato. La práctica estándar es ir al 1% el día 1 mientras monitoreas la tasa sin crashes y los ANRs en vivo, al 10% el día 3 si las métricas están dentro del presupuesto, al 50% para el día 7 y al 100% para el día 10. Tanto el release por fases de App Store Connect como los rollouts escalonados de Play Console lo hacen trivial. En el momento en que una métrica rompa el presupuesto, detente e investiga.
Rendimiento Percibido vs Técnico
El rendimiento técnico es una medición; el rendimiento percibido es una emoción. Correlacionan, pero no de forma limpia. Un usuario que espera 800ms con una pantalla skeleton siente que la app es rápida. Un usuario que espera 400ms mirando una pantalla blanca en blanco siente que está rota. El segundo caso tiene mejores métricas técnicas y peor rendimiento percibido.
Técnicas que mejoran la percepción sin cambiar la latencia
Las pantallas skeleton muestran la forma del contenido antes de que llegue. Facebook fue pionero en el patrón, y hace que las redes lentas se sientan aceptables. La UI optimista confirma la acción del usuario visualmente antes de que el servidor confirme, revirtiendo con un toast si falla; el botón de like de Twitter es el ejemplo canónico. La carga progresiva renderiza las partes baratas primero (texto, layout) y hace streaming de las partes caras (imágenes, módulos personalizados). La confirmación háptica usa un háptico sutil en el toque para confirmar que la acción se registró aunque la pantalla no se haya actualizado, y el
de iOS y los de Android hacen esto trivial. El prefetch predictivo obtiene los datos de la probable próxima pantalla mientras el usuario aún está en la pantalla actual.Cómo el session replay muestra la brecha
Las métricas técnicas te dicen que la API retornó en 300ms. El session replay muestra al usuario tocando, esperando, tocando de nuevo, tocando por tercera vez porque nada cambió visiblemente. Ese es un problema de rendimiento percibido que nunca encontrarías en un dashboard de APM, y es la razón por la cual emparejar UXCam con un APM técnico funciona mejor que cualquiera solo.
El modelo de madurez de rendimiento
La mayoría de los equipos está en la etapa 1 o 2. Muy pocos alcanzan la etapa 4. Saber en qué etapa estás te dice en qué trabajar a continuación.
Etapa 0: Sin instrumentación. Los crashes vienen de la revisión de Apple o de tweets de usuarios. Las discusiones de rendimiento son basadas en sensaciones, y "la app se siente lenta" es un reporte de bug válido. La mayoría de las startups en etapa temprana viven aquí.
Etapa 1: Crash reporting básico. Firebase Crashlytics o Sentry está instalado, y alguien monitorea la tasa sin crashes ocasionalmente. Todavía no hay tracking de cold start o ANR. Las regresiones de rendimiento se notan en retrospectiva.
Etapa 2: APM instalado, los dashboards existen. Un dashboard de rendimiento existe, el cold start y los crashes y la latencia de red se monitorean, pero nadie los mira semanalmente. Las regresiones se notan cuando alguien se queja. La mayoría de las empresas en etapa media están aquí.
Etapa 3: El rendimiento es responsabilidad de un equipo. Un equipo de rendimiento o ingeniero dedicado es dueño de los dashboards, establece presupuestos y revisa los releases. Las regresiones se atrapan en días, el session replay se empareja con métricas, y los usuarios ven mejoras trimestrales tangibles. Aquí es donde pasan las grandes victorias de confiabilidad.
Etapa 4: Presupuestos de perf forzados en CI, responsabilidad de cada equipo. Cada equipo de feature es dueño del rendimiento de su superficie, los presupuestos se hacen cumplir en CI, y las regresiones bloquean los merges. Cada release tiene una revisión de perf junto con la revisión de producto. El rendimiento es un pilar de producto de primer nivel, no una preocupación de ingeniería. Las apps en esta etapa (los equipos móviles de Lyft, Airbnb, Uber) publican posts de blog de ingeniería sobre su práctica.
10 errores comunes de rendimiento móvil
Estos son patrones que veo repetirse durante auditorías.
Iniciar demasiados SDKs en el cold start. Analytics, ads, feature flags, crash reporter, session replay, push, A/B testing y SDK de auth todos inicializados síncronamente en
. Difiere todo lo que no sea necesario antes del primer frame.Red síncrona en el main thread. Incluso una llamada bloqueante en el thread de UI causa un ANR en redes lentas. Usa coroutines, concurrencia estructurada o async/await de Swift.
Bitmaps de arranque de gran tamaño. Un splash screen PNG de 4MB decodificado en el main thread agrega 600ms al cold start en Android de gama media. Usa vector drawables y la API de splash screen de Android 12.
Caching de imágenes sin límites. Cargar una imagen 4K en un ImageView de 400px sin downsampling quema memoria. Toda librería de imágenes tiene opciones de resize; úsalas.
Ignorar dispositivos con poca memoria. Probar solo en tu celular flagship personal. El dispositivo con 2GB de RAM es el 30% de tus usuarios y el 60% de tus reseñas de 1 estrella.
Sin retry o backoff en fallas de red. Una conexión inestable se convierte en un error permanente porque la app no reintenta. Usa backoff exponencial con jitter.
Bloquear la primera pantalla en una llamada de refresh de auth. Si el refresh falla, el usuario ve un spinner de carga para siempre. Renderiza desde cache, refresca en segundo plano.
Emitir demasiados eventos de analytics. Agrupar 200 eventos por minuto sin compresión quema batería y bandwidth. Usa la ventana de batching del SDK, no HTTP por evento.
Layout thrashing en listas. RecyclerView o SwiftUI List recalculando layouts caros en cada frame de scroll. Perfila con Layout Inspector o Instruments.
Ignorar el crecimiento del tamaño de la app. Cada nueva librería agrega megabytes, y una app de 200MB tiene una conversión de instalación significativamente menor que una app de 40MB. Audita con Android Studio APK Analyzer y App Thinning.
Entendiendo las Métricas de Rendimiento
Cada métrica responde una pregunta diferente. Cold start, tasa de frames, memoria y latencia de API te dicen qué tan rápida es la app. La tasa sin crashes, la tasa de ANR y la tasa de congelamientos de UI te dicen qué tan confiable es. La tasa de rage taps y las observaciones de session replay te dicen cómo se siente la app para los usuarios. La retención, la duración de sesión y DAU/MAU te dicen si los usuarios están volviendo. El CAC, el ROAS y el LTV:CAC te dicen si el negocio es eficiente.
Los mejores dashboards de rendimiento eligen 2-3 métricas de cada categoría para que tengas una imagen completa en 10-12 números.
Cómo Medir el Rendimiento de Apps Efectivamente
Empieza instalando un SDK de analytics que capture estas métricas automáticamente. UXCam, Firebase Analytics más Performance, Sentry o Mixpanel todos funcionan. La instrumentación manual lleva semanas y atrapa una fracción de lo que hace la auto-captura.



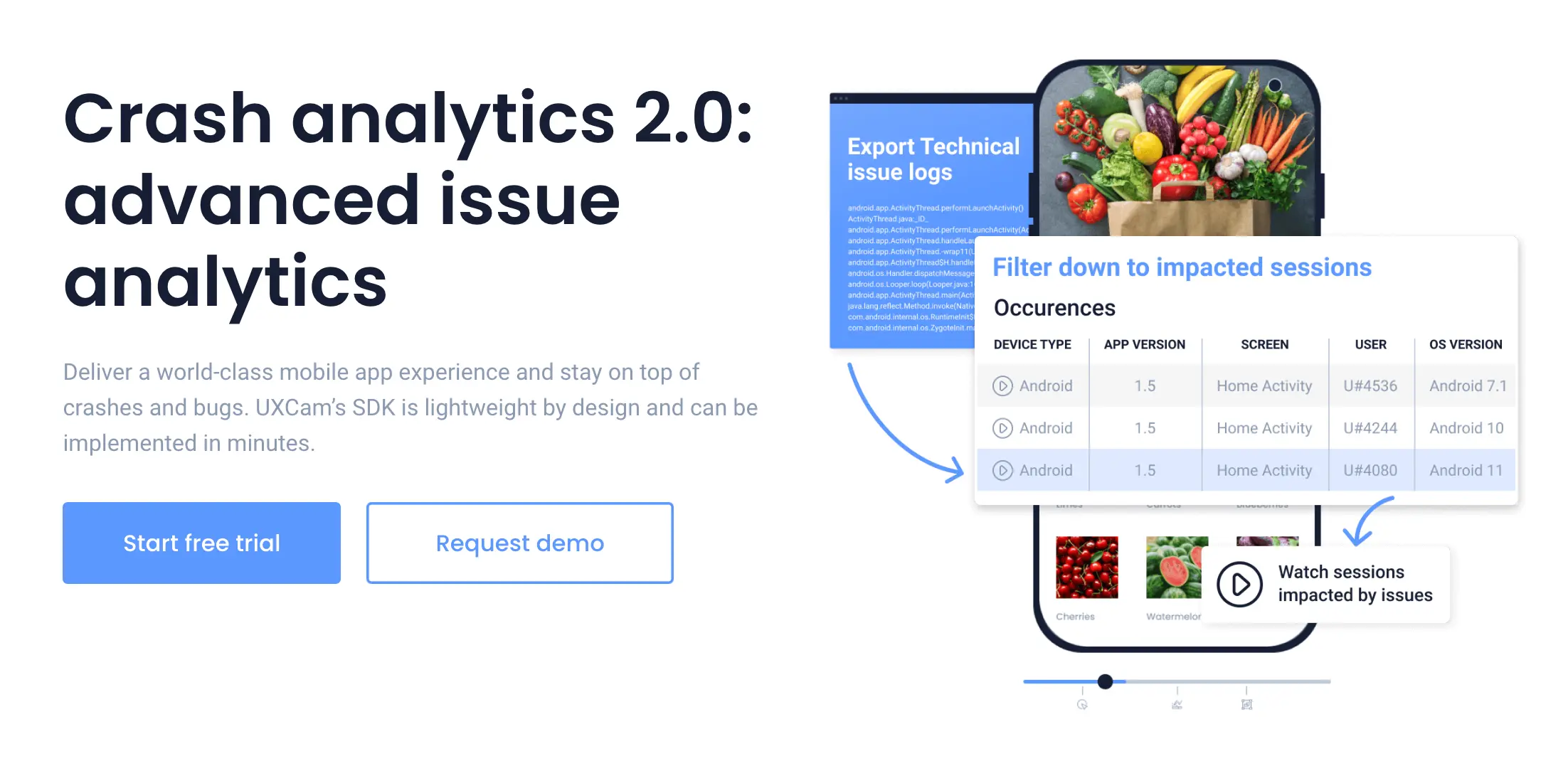
Luego segmenta por clase de dispositivo, versión de OS y geografía, porque las métricas agregadas ocultan patrones reales. Un cold start de percentil 95 que se ve genial en general podría ocultar un rendimiento terrible en el 30% de usuarios en Android de gama media.
Revisa el dashboard semanalmente con el equipo de producto. El rendimiento no es solo una métrica de ingeniería: las decisiones de producto sobre qué pantalla hacer por defecto, qué feature agregar, cuánto onboarding mostrar, todas afectan al rendimiento directamente. Establece alertas para regresiones para que cuando la tasa sin crashes caiga por debajo del umbral o el cold start se pase del objetivo, alguien reciba la alerta. Las regresiones silenciosas se acumulan más rápido de lo que cualquiera espera.
Finalmente, empareja las métricas cuantitativas con el session replay. Los números te dicen que algo se movió; los replays te dicen qué estaban experimentando los usuarios en realidad. El session replay de UXCam más Tara AI hacen este workflow automático.
Mide el rendimiento de tu app móvil con UXCam
UXCam es una plataforma de product intelligence y product analytics que captura automáticamente cada interacción del usuario en aplicaciones móviles y sitios web, sin etiquetado manual de eventos. El tiempo de cold start, la tasa sin crashes, la duración de sesión, la tasa de rage taps, la tasa de congelamientos de UI y todas las demás métricas de esta lista se monitorean de fábrica. Issue Analytics muestra los problemas de rendimiento en tiempo real y los rankea por cuántos usuarios están afectados, y Tara, la analista de IA de UXCam, procesa sesiones para recomendar correcciones específicas, dando a los equipos insights basados en evidencia y la evidencia para convencer a los stakeholders.
Inspire Fitness usó este workflow para aumentar el tiempo en app en un 460% y reducir los rage taps en un 56%. PlaceMakers identificó un problema de rendimiento, probó una corrección y validó el resultado en 3 días. El SDK de UXCam ha sido refinado por 9+ años, está por debajo de 300KB, usa menos del 5% de CPU y está instalado en 37.000+ productos.
Solicita una demo para verlo en tu app.
Preguntas frecuentes
¿Qué son las métricas de rendimiento de apps móviles?
Las métricas de rendimiento de apps móviles son las señales cuantitativas que miden qué tan rápida, confiable y atractiva se siente una aplicación móvil para los usuarios. Abarcan cinco capas: rendimiento técnico (tasa de frames, memoria), rendimiento de arranque (cold start), confiabilidad (tasa sin crashes), rendimiento de negocio (retención, CAC) y rendimiento percibido (rage taps, congelamientos de UI).
Monitorear al menos una métrica de cada capa te da una imagen completa de la salud de la app.
¿Cómo se mide el rendimiento de una app móvil?
Instala un SDK de analytics que capture las métricas automáticamente, como UXCam, Firebase Performance o Sentry. Segmenta por clase de dispositivo, versión de OS y geografía para encontrar patrones que los datos agregados ocultan, y revisa semanalmente con producto e ingeniería.
Empareja las métricas cuantitativas con session replay para entender qué experimentan realmente los usuarios, y establece alertas para regresiones en métricas críticas como tasa sin crashes y cold start.
¿Cuál es un buen tiempo de cold start para una app móvil?
Un p95 por debajo de 2 segundos es bueno, por debajo de 1.5 es excelente, y por encima de 3 segundos perjudica la retención de primera sesión de forma medible. Monitorea el percentil 95, no la mediana, porque los usuarios en dispositivos y redes más lentos son los más vulnerables al churn.
Esos usuarios suelen ser los peor servidos por tu app, así que arreglar su experiencia importa desproporcionadamente.
¿Cuál es la diferencia entre rendimiento de app móvil y analítica de app móvil?
El rendimiento de una app móvil es un subconjunto de la analítica de app móvil. El rendimiento cubre la velocidad técnica y percibida, la confiabilidad y la experiencia de usuario de que la app funcione bien. La analítica cubre el conjunto más amplio de métricas incluyendo engagement, retención, ingresos y adquisición.
Todas las métricas de rendimiento son métricas de analítica, pero no todas las métricas de analítica son sobre rendimiento.
¿Qué métrica de rendimiento de app móvil es la más importante?
El tiempo de cold start para la retención temprana, la tasa de usuarios sin crashes para la confiabilidad y la tasa de rage taps para el rendimiento percibido. Si tuviera que elegir una en general, es la tasa de usuarios sin crashes, porque un crash en la primera sesión de un usuario aproximadamente triplica su probabilidad de churn.
AUTOR
Silvanus Alt, PhD
Founder & CEO | UXCam
Silvanus Alt, PhD, is the Co-Founder & CEO of UXCam and a expert in AI-powered product intelligence. Trained at the Max Planck Institute for the Physics of Complex Systems, he built Tara, the AI Product Analyst that not only analyzes user behavior but recommends clear next steps for better products.



TABLA DE CONTENIDO
- Conclusiones clave
- El catálogo de métricas de rendimiento
- Bonus: las métricas de capa de negocio
- Presupuestos de Rendimiento por Plataforma
- Herramientas APM y RUM comparadas
- Benchmarking por clase de dispositivo
- Atrapando regresiones de rendimiento en CI/CD
- Rendimiento Percibido vs Técnico
- El modelo de madurez de rendimiento
- 10 errores comunes de rendimiento móvil
- Entendiendo las Métricas de Rendimiento
- Cómo Medir el Rendimiento de Apps Efectivamente
- Mide el rendimiento de tu app móvil con UXCam
- Preguntas frecuentes



Artículos relacionados
Conversion Analysis
Cómo Medir el Rendimiento de una App Móvil: 18 Métricas Que Importan (2026)
Las métricas de rendimiento de apps móviles miden qué tan rápida, confiable y atractiva se siente una aplicación para los...
Silvanus Alt, PhD
Founder & CEO | UXCam


Conversion Analysis
Conversion Funnel Analysis: Guía Completa para 2026
El conversion funnel analysis es como los equipos de producto encuentran dónde los usuarios abandonan flujos críticos como signup, checkout y activación,...
Silvanus Alt, PhD
Founder & CEO | UXCam



Conversion Analysis
LogRocket vs Sentry: funcionalidades, precios y la mejor alternativa
LogRocket vs Sentry comparados en funcionalidades, precios y casos de uso. Además, una alternativa para mobile y web con session replay, heatmaps y...
Silvanus Alt, PhD
Founder & CEO | UXCam